Introduction
This document details how to install, configure and administrate Cosmos (and its ecosystem) and Sinfonier, the BigData Analysis Generic Enabler (BigData Analysis GE) reference implementations (GEri).
The BigData Analysis GE, as described in the Architecture Description, is intended to deploy means for analyzing both batch and stream data (in order to get, in the end, insights on such a data). These two different aspects of the GE lead to the usage of two specialized set of tools:
- Cosmos (either the official one based on Openstack's Sahara, either the light version based on a shared Hadoop cluster), Tidoop and Cygnus, conforming the Cosmos Ecosystem, for batch processing.
- Storm and Sinfonier for stream processing.
Nevertheless, and according to the current versions of the software, please observe both set of tools are not necessary at the same time. So you can feel free to install one, the other or both. Even, not all the tools within a set are mandatory; please have a look on the description of each tool in order to know wether it suits for your deployment or not.
Intended audience
This document is mainly addressed to those service providers aiming to expose a BigData Analysis GE-like services. For those service providers, the data analysis is not a goal itself but providing ways others can perform such data analysis. This especially applies to Openstack's Sahara and Sinfonier installation.
If you are a data scientist willing to get some insights on certain data; or you are a software engineer in charge of productizing an application based on a previous data scientist analysis, then please visit the User and Programmer Guide; and/or go directly to the FIWARE Lab global instance of Cosmos, there you will find an already deployed infrastructure ready to be used through the different APIs.
If you don't relay on FIWARE LAB global instance of Cosmos and you want to use Hadoop, do not install Cosmos; that will be as installing a complete Cloud just for creating a single virtual machine. Instead, simply install a private instance of Hadoop!
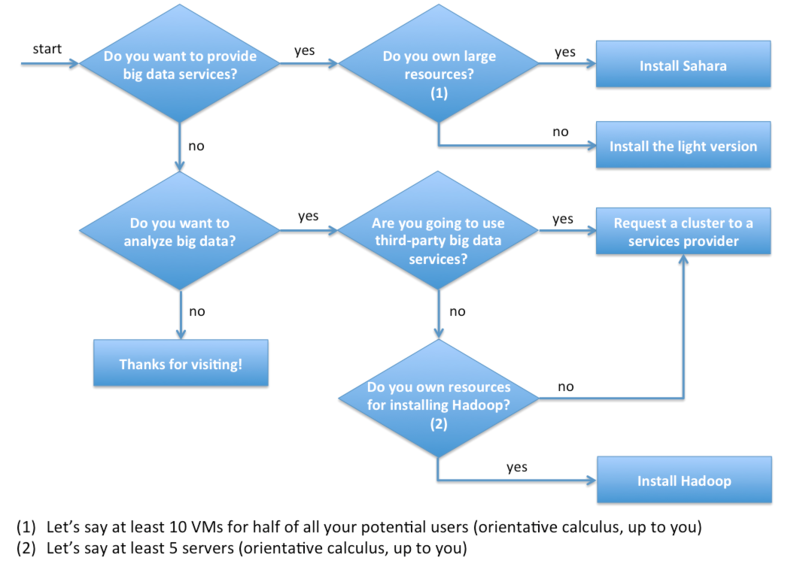
If you still have doubts, we have built the flow diagram below in order to help you identifying which kind of Big Data user you are (if any):
Structure of the document
Apart from this introduction, this Installation and Administration Guide contains two main sections, one for batch and another one for stream analysis. Within each main section, there are specific topics regarding the tools involved; in addition, sanity check procedures (useful to know wether the installation was successful or not) and diagnosis procedures (a set of tips aiming to help when an issue arises) are provided as well.
Reference repositories in Github
Apart from this repository (http://github.com/telefonicaid/fiware-cosmos), the following ones will be linked constantly through the whole document; hey are listed here for a clear reference:
Reporting issues and contact information
There are several channels suited for reporting issues and asking for doubts in general. Each one depends on the nature of the question:
- Use stackoverflow.com for specific questions about the GE/GEri. Typically, these will be related to installation problems, errors and bugs. Development questions when forking the code are welcome as well. There are several tags that can be used to categorize the issue:
- fiware-cosmos
- fiware-tidoop
- fiware-cygnus
- fiware-sinfonier
- storm (please observe in this case we are not the main supporters of Apache Storm)
- Use ask.fiware.org for general questions about FIWARE, e.g. how many cities are using FIWARE, how can I join the accelerator program, etc. Even for general questions about this software, for instance, use cases or architectures you want to discuss.
- Personal email:
- francisco.romerobueno@telefonica.com (Cosmos Ecosystem)
- franciscojesus.gomezrodriguez@telefonica.com (Sinfonier)
NOTE: Please try to avoid personally emailing the GE owners unless they ask for it. In fact, if you send a private email you will probably receive an automatic response enforcing you to use stackoverflow.com or ask.fiware.org. This is because using the mentioned methods will create a public database of knowledge that can be useful for future users; private email is just private and cannot be shared.